Un data science pipeline framework est essentiel pour mener à bien des projets de machine learning. Il structure les étapes, facilite la collaboration et garantit la reproductibilité. Dans ce contexte, Kedro s’impose comme un outil puissant pour les data scientists. Grâce à sa structure modulaire, il permet de concevoir, maintenir et déployer des workflows ML de manière propre, traçable et professionnelle. Cet article présente Kedro, ses atouts dans un pipeline de data science, et sa complémentarité avec d’autres outils comme MLflow dans une logique MLOps.
1. Comprendre le data science pipeline framework
Qu’est-ce qu’un pipeline data science ?

Un pipeline data science est une suite d’étapes organisées permettant de transformer des données brutes en prédictions exploitables. Cela inclut la collecte des données, leur nettoyage, leur exploration, la modélisation, l’évaluation, et enfin, le déploiement du modèle.
Pourquoi utiliser un framework ?
Un data science pipeline framework permet de structurer ce processus. Il favorise la reproductibilité, la collaboration et la qualité du code. Sans framework, les projets deviennent souvent désorganisés, non testables et difficilement déployables.
2. Kedro : le framework Python pour structurer vos projets ML
Présentation de Kedro
Kedro est un framework Python open-source conçu pour appliquer les bonnes pratiques d’ingénierie logicielle aux projets de data science. Il organise le code, les données et les configurations en modules clairs et réutilisables.
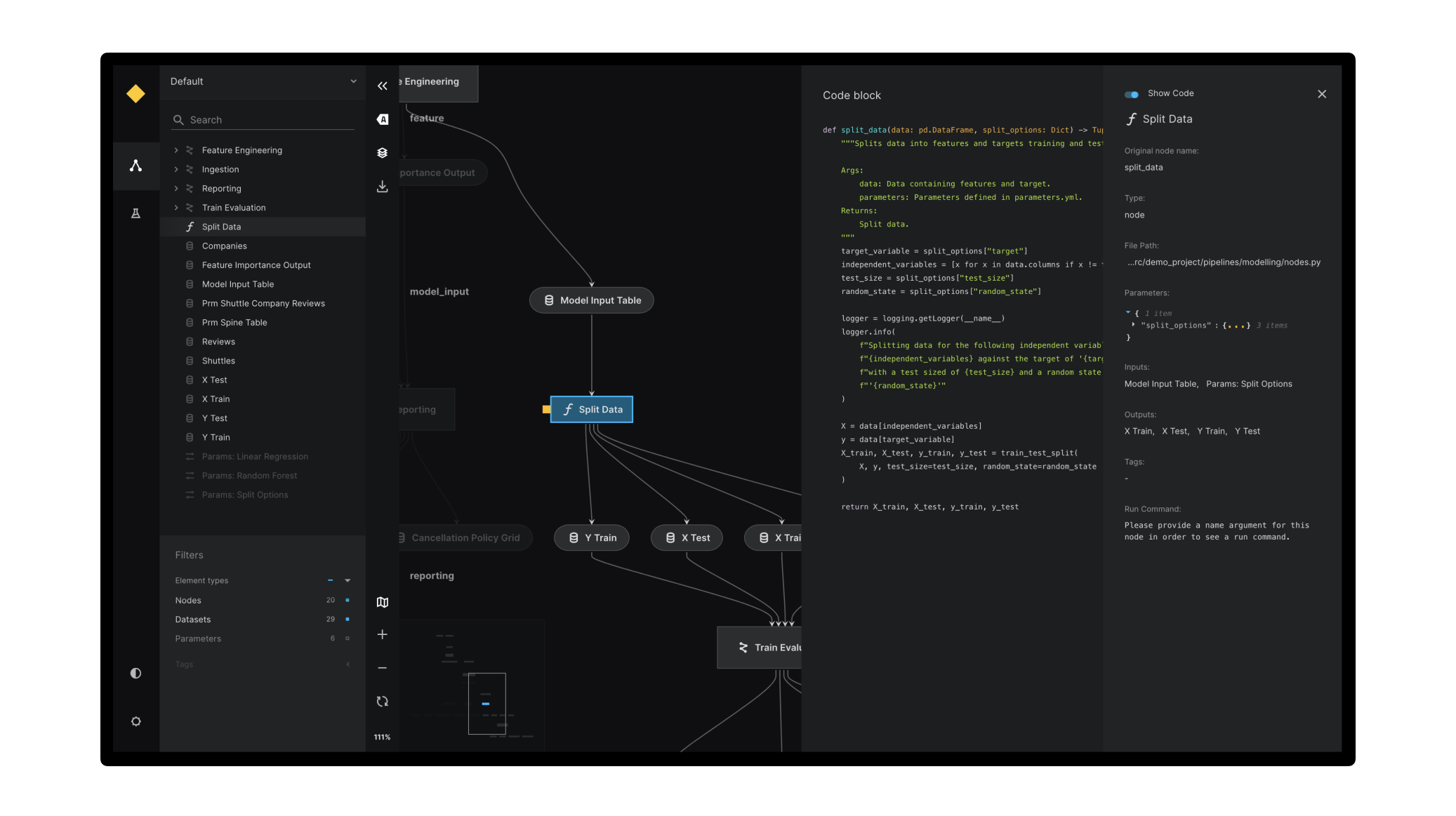
Un pipeline modulaire et traçable
Avec Kedro, chaque étape du pipeline est définie comme un nœud. L’ensemble forme un graphe de dépendances. Cela rend le pipeline transparent, traçable, et facile à debugger. Les flux de données sont clairs, et l’on peut facilement réexécuter seulement les parties concernées.
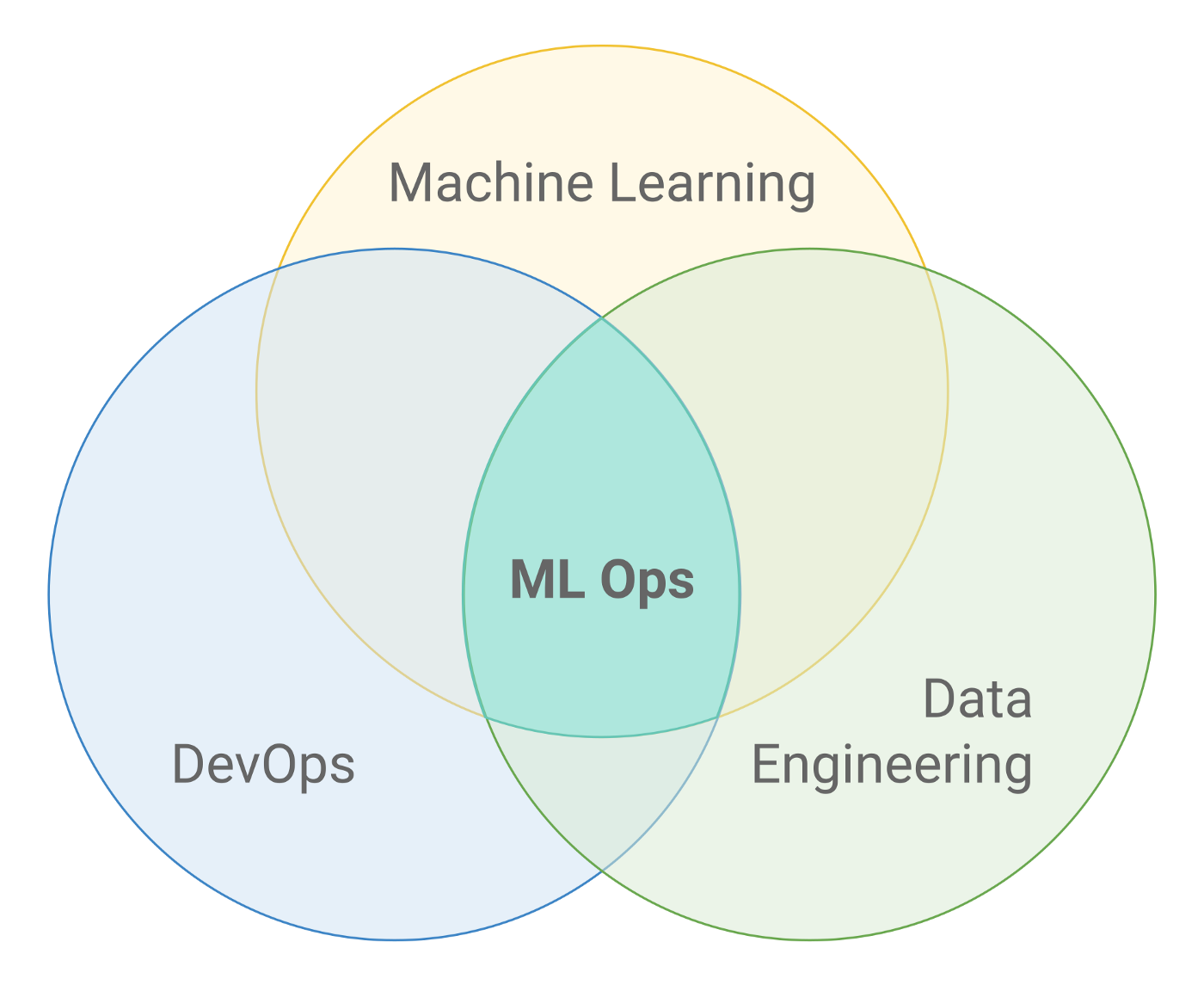
3. Avantages d’un pipeline Kedro dans un workflow MLOps
Intégration dans les workflows ML modernes
Kedro s’intègre parfaitement dans un workflow MLOps. Il est compatible avec des orchestrateurs comme Airflow, Prefect, ou encore Argo Workflows. On peut automatiser l’exécution des pipelines, et intégrer des étapes de validation ou de test.
Compatibilité CI/CD
Grâce à sa structure claire, Kedro est idéal pour le CI/CD. Les pipelines peuvent être testés à chaque push dans un dépôt Git, validés automatiquement, et déployés dans un environnement de production. Cela réduit les erreurs humaines et accélère les cycles de développement.
4. Kedro vs MLflow : rôles et complémentarités
Deux outils, deux objectifs
- Kedro structure le pipeline. Il organise les tâches, les entrées, les sorties et la logique.
- MLflow gère l’expérimentation. Il suit les hyperparamètres, les métriques, les modèles et les versions.
Intégration possible
Il existe des plugins comme kedro-mlflow permettant d’intégrer les deux outils. Ainsi, on bénéficie d’une structure propre et d’un suivi précis des performances. Ce couplage est idéal pour les équipes cherchant à industrialiser leurs projets.
5. Vers un responsible data science framework
Reproductibilité et auditabilité
Un framework comme Kedro contribue à une data science responsable. Il impose des standards, favorise la documentation du code et permet de reproduire des résultats des mois plus tard. Cela est crucial dans des contextes réglementés ou sensibles.
Sécurité et collaboration
La séparation stricte entre les données, la logique et la configuration rend le projet plus sécurisé. On peut partager le pipeline sans exposer les données. Les équipes peuvent travailler de manière collaborative, sans écraser le travail des autres.
FAQ – Questions fréquentes sur les data science pipeline frameworks
Qu’est-ce qu’un data science pipeline framework ?
C’est une structure qui organise toutes les étapes d’un projet ML, de la collecte des données à la mise en production du modèle.
Kedro est-il adapté aux projets professionnels ?
Oui. Kedro applique les meilleures pratiques de l’ingénierie logicielle aux projets ML : modularité, tests, logs, CI/CD, structure claire.
Quelle est la différence entre Kedro et MLflow ?
Kedro structure les pipelines, MLflow suit les expériences. Ils sont souvent utilisés ensemble dans un workflow complet.
Peut-on automatiser un pipeline Kedro ?
Oui. Kedro s’intègre avec des outils comme Airflow, Prefect ou GitHub Actions pour automatiser l’exécution des tâches.
Kedro est-il un framework de data science responsable ?
Oui. Il favorise la traçabilité, la reproductibilité, la séparation des environnements, et l’auditabilité des modèles.
commentaires